
What is Loss Run Automation?
By SortSpoke

DEFINITION:
Loss run automation applies artificial intelligence, machine learning, and human validation processes to automatically extract, standardize, and analyze claim history data from insurance loss run reports.
This technology enables faster, more consistent underwriting decisions while maintaining accuracy and compliance.
In today's competitive insurance landscape, underwriters spend up to 40% of their time manually processing and analyzing loss runs – historical claim records that are critical for risk assessment and pricing decisions. This time-intensive process creates significant bottlenecks, especially as submission volumes increase and skilled underwriting talent becomes harder to find.
For insurance leaders looking to scale operations without proportionally increasing headcount, loss run automation presents a compelling opportunity. But what exactly is loss run automation, how does it work, and what benefits can you realistically expect? This comprehensive guide answers these questions and provides insights into this transformative technology.
Published March 24, 2025 | Updated July 21, 2026
DEFINITION:
Loss run reports, or Loss Runs, are detailed reports documenting an insured's claim history over a specific period (typically 3–5 years), including claim dates, types, amounts paid, reserves, and current status.
Loss runs are provided by current or previous insurance carriers and are essential for underwriting new or renewal business.
Loss runs are historical claim records that provide detailed information about an insured's past losses. These documents serve as the foundation for underwriting decisions, helping insurers evaluate risk profiles, determine appropriate coverage terms, and set accurate premium rates.
While digital transformation has modernized many aspects of insurance operations, loss runs remain a critical component of the underwriting process. They provide the historical context needed to make informed decisions about future risk exposure.
Loss runs typically contain the following information:

The challenge lies in the lack of standardization across the industry. Loss runs come in various formats depending on the carrier or third-party administrator (TPA) that produced them. They may arrive as PDFs, scanned documents, Excel spreadsheets, or even as images embedded in emails.
The analysis of loss runs goes beyond simply extracting data points. Underwriters must identify patterns, frequency trends, severity indicators, and potential red flags that might indicate future risk. This analysis directly impacts:
Moreover, proper documentation of loss run analysis is increasingly important for regulatory compliance and audit purposes. Underwriters must be able to demonstrate that they thoroughly reviewed historical claims data when making decisions.
The conventional approach to processing loss runs involves several manual steps:
Collecting loss runs from various sources and sorting them by submission. Underwriters often need to follow up with brokers for missing information or additional details.
Scanning documents to identify relevant information and determine whether they contain the necessary data for underwriting analysis.
Manually transcribing key data points from documents, often requiring careful attention to detail across multiple pages and tables.
Inputting extracted information into underwriting systems, which may involve copying data across multiple platforms.
Evaluating patterns, calculating loss ratios, and identifying trends that indicate risk levels and pricing considerations.
Developing loss summaries for decision-making that can be referred to by multiple stakeholders in the underwriting process.
Incorporating findings into the broader underwriting assessment and connecting loss run insights with other risk factors.
This process is not only time-consuming but also prone to inconsistency as different underwriters may extract and interpret information differently.
The manual processing of loss runs consumes significant underwriting resources:

For a typical commercial lines carrier processing 1,000 submissions monthly, this translates to approximately 500-1,000 hours of underwriter time spent solely on loss run processing – time that could be better allocated to risk assessment, relationship building, and higher-value analytical work.
The traditional approach presents several challenges:
Loss run automation uses technology to streamline the extraction, processing, and analysis of data from loss run documents. Unlike simple document digitization, comprehensive loss run automation addresses the full workflow from receipt to analysis.
A complete loss run automation solution includes:
Loss run processing technology has evolved significantly:

Each evolution has addressed the limitations of previous approaches, with the current generation focusing on flexibility, accuracy, and maintaining underwriter control.
| Approach | Strengths | Limitations |
|---|---|---|
| Manual processing (Onshore or Offshore) |
- Human expertise applies - No technology investment required - Adaptable to any document format |
- Extremely time-intensive - Slow turn around times - Difficult to scale - Manual review is error-prone |
| Traditional OCR | - Handles digital-native PDFs - Works with consistent formats - Simple to implement |
- Fails with varied document formats - Struggles with scanned documents - Requires template creation - No contextual understanding |
| Rules-Based Systems | - More flexible than pure OCR - Can handle some variation - Explainable logic |
- Requires extensive rule creation - Breaks when formats change - High maintenance cost - Limited adaptability |
| ML-Only Solutions | - Handles varied formats - Improves with more data - Adapts to new formats |
- May miss contextual nuances - Requires substantial training data - Limited explainability |
| LLM-Only Approaches | - Strong contextual understanding - Handles complex language - Flexible with formats |
- Potential hallucinations - Unpredictable extraction - Black-box decision making - Compliance concerns |
| Human-in-the-Loop AI | - Highest accuracy and reliability - Continuous improvement - Maintains underwriter control - Adaptable to all formats - Full auditability and compliance |
- Requires thoughtful implementation - Needs proper validation workflows - More sophisticated than basic OCR |
The most effective approach combines the strengths of machine learning, large language models, and human expertise while mitigating their individual limitations.
Loss run automation delivers significant time savings and throughput improvements:
For carriers processing thousands of submissions monthly, these efficiency gains translate directly to competitive advantage through faster quote turnaround and higher capacity.
Beyond speed, automation improves the quality and reliability of loss run processing:
These quality improvements lead to better underwriting decisions based on more accurate and complete historical loss data.

Loss run automation creates strategic advantages beyond tactical efficiency:
These benefits compound over time as the automated system continues to learn and improve from human feedback.
Modern insurance operations face increasing regulatory scrutiny and documentation requirements. Loss run automation provides:
This documentation becomes increasingly valuable as regulatory requirements evolve and audits become more thorough.
Most conversations about loss run automation focus on how the AI extracts data. Just as important, though, is where your team actually interacts with it. Many solutions ask underwriters to log into yet another portal, learn a new interface, and shuttle data back and forth between disconnected systems – adding friction to the very workflow the automation was supposed to simplify.
The alternative is an embeddable approach: loss run automation that runs inside the tools your team already uses every day. Rather than sending underwriters to a separate application, the AI extracts, standardizes, and surfaces loss run data directly within your existing environment – whether that's your underwriting workbench, policy administration system, email inbox, or a broker-facing submission portal. The document AI does the extraction; your underwriters review and decide, all without leaving the screen they already work in.
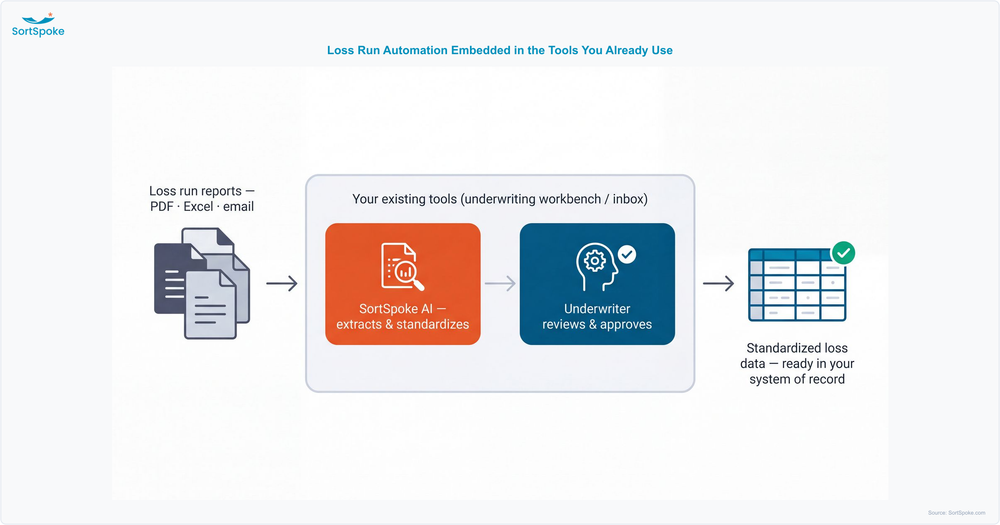
This embeddable architecture reflects a straightforward principle: the AI should meet your team where they already work. When loss run automation lives inside your existing tools instead of alongside them, the technology fades into the background – underwriters simply see cleaner, standardized loss data appear in the workflow they already know, ready for their review.
Here's what that looks like in practice. Below, document extraction runs inside an underwriting workbench: the loss run report sits alongside the fields the AI pulled from it – claim number, claimant, paid and reserved amounts, loss location – each traceable back to its spot on the page. Where a value is missing or low-confidence, the underwriter is prompted to review and correct it, then approve the document, all without ever leaving the workbench.
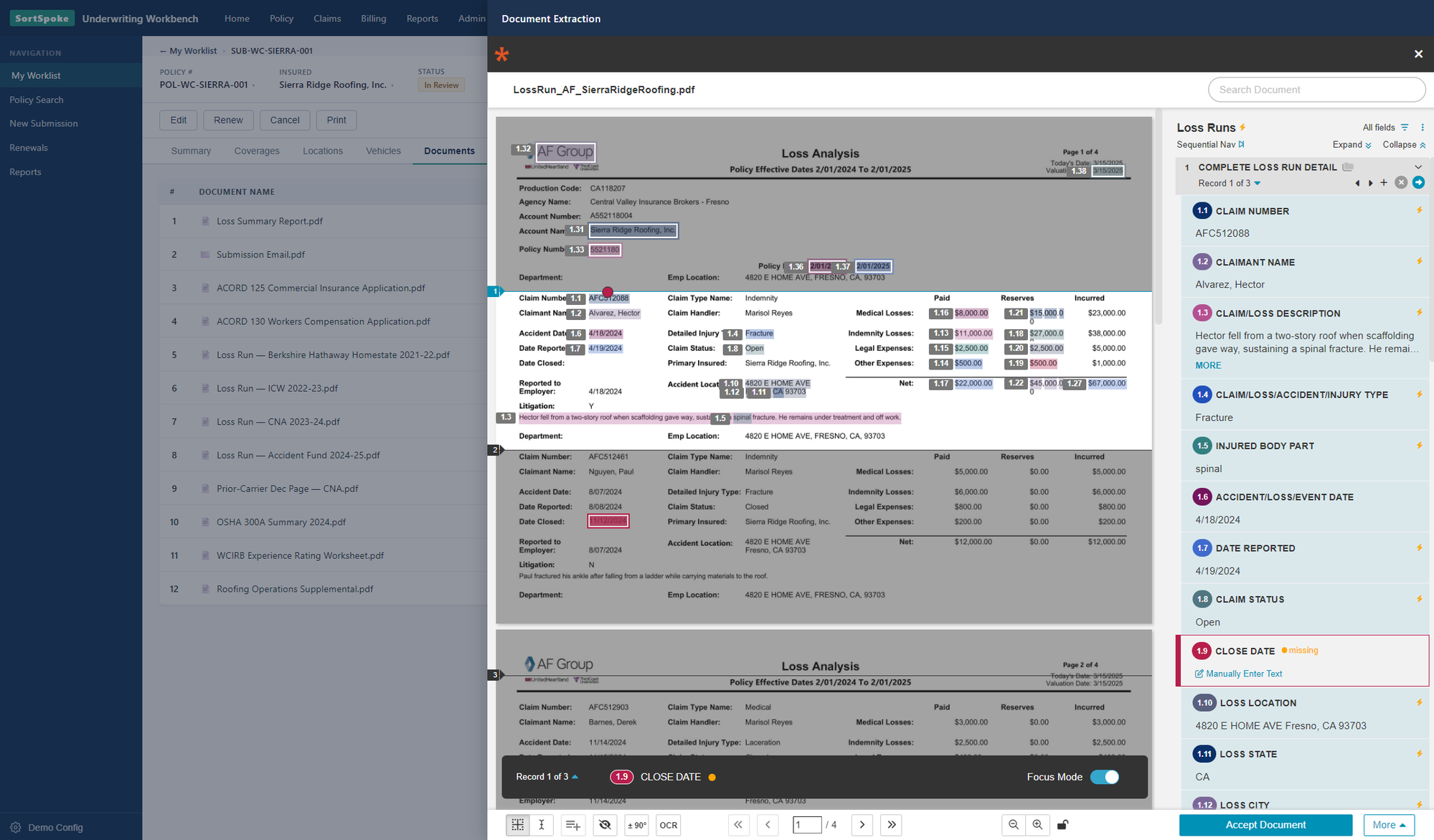
Document extraction running inside an underwriting workbench. The loss run report opens in place (left), while every claim field the AI captured — claim number, claimant, paid, reserved and incurred amounts, injury type, loss location — appears on the right, each linked back to its exact spot on the page. Low-confidence or missing values (here, a "missing" Close Date) are flagged for the underwriter to review and correct before they click Accept Document — no separate portal, no re-keying into the system of record.
Machine learning provides the foundation for identifying patterns and extracting structured data:
ML models can be trained on insurance-specific documents to recognize industry terminology and common formats, providing a level of flexibility impossible with traditional OCR or rule-based systems.
LLMs add contextual understanding and natural language processing capabilities:
This contextual understanding allows for more accurate extraction, especially when dealing with complex or non-standard loss run formats.
The human element remains essential for quality, compliance, and continuous improvement:
This collaborative approach between AI and underwriters ensures accuracy while continuously improving the system's performance.
The future of loss run automation is centered on underwriting teams partnering effectively with AI:
These evolving partnerships will redefine underwriting workflows, combining the pattern recognition strengths of AI with the critical judgment and experience of skilled underwriters. Rather than replacing the human element, next-generation automation will enhance it, creating more powerful and effective underwriting teams.
Loss run automation represents a critical capability for modern insurance organizations seeking to improve efficiency, maintain quality, and scale operations. By combining the best of AI technology with human expertise, insurers can transform a significant bottleneck into a strategic advantage.
The most successful implementations will:
As submission volumes increase and skilled underwriting talent becomes scarcer, the ability to process loss runs efficiently while maintaining accuracy becomes not just an operational advantage but a competitive necessity.
Commercial P&C Insurers Guide to Solving the Underwriting Bottleneck




