
The Exception Economy: Why Insurance Document Processing Will Never Be Fully Autonomous
By Brandon Robinson

Every vendor pitching insurance AI right now leads with the same slide: an accuracy number. 97%. 99.2%. Some impressive percentage with a confident decimal point.
Here's what regulators don't ask about: the accuracy number.
The NAIC, Colorado, New York's Department of Financial Services, and the EU AI Act have all converged on the same short list of demands — and "how accurate is your model" isn't on it. If you are a Chief Compliance Officer, General Counsel, or Head of Underwriting Ops sponsoring an AI project, the gap between what your vendor is selling and what an examiner will ask for is the most expensive thing on your roadmap that nobody has priced in yet.
Accuracy is the easiest thing to measure and the easiest thing to sell. It fits on a slide, sounds like progress, and lets a buyer feel like due diligence is done. The problem is that it answers a question no regulator is asking.
A model can be 99% accurate and still produce a disparate impact on a protected class. It can be 99% accurate and leave no record of why it reached a decision. It can be 99% accurate and take an action no authorized human ever reviewed. None of those failures show up in the accuracy number — and every one of them is exactly what an examiner is trained to find.
This is the same disconnect we see when carriers evaluate intake tools on extraction accuracy alone. We've argued before that insurance-specific AI with HITL outperforms generic models precisely because the score on a benchmark is not the thing that determines whether the system holds up in production — or in an exam.
Read the NAIC Model Bulletin, Colorado's Regulation 10-1-1, New York's circular-letter guidance, and the EU AI Act side by side and a pattern emerges. They use different words, but they ask for the same three things.
Notice what's absent. There's no requirement to hit a model-performance threshold. The frameworks don't certify your AI as "good enough." They ask whether you can explain and account for what it did. That distinction is the whole game.
"Many of the laws that DFS enforces are technology-agnostic, meaning the core regulatory obligations are the same for manual processes as they are for AI models and systems."
— Acting Superintendent Kaitlin Asrow, NY Department of Financial Services, statement to the NY State Assembly, December 16, 2025
Translation: regulators are not, for the most part, writing brand-new rules for AI. They are applying the existing body of unfair-discrimination, model-risk, and consumer-protection law to AI outputs (NY DFS, December 2025). And that body of law was written assuming a human was accountable at the decision point. When you remove the human, you don't escape the obligation — you just lose the evidence that you met it.
If this still feels theoretical, look at the dates. The regulatory tide stopped being a forecast and became a calendar:
Some of this is enforced now (Colorado, the adopted NAIC bulletins). Some is roughly two budget cycles away (third-party model registration, the matured NAIC evaluation framework). The carriers that treat the imminent items as "later" are the ones who will be assembling an audit trail retroactively — which, as anyone who has tried it knows, is the hardest possible way to produce one.
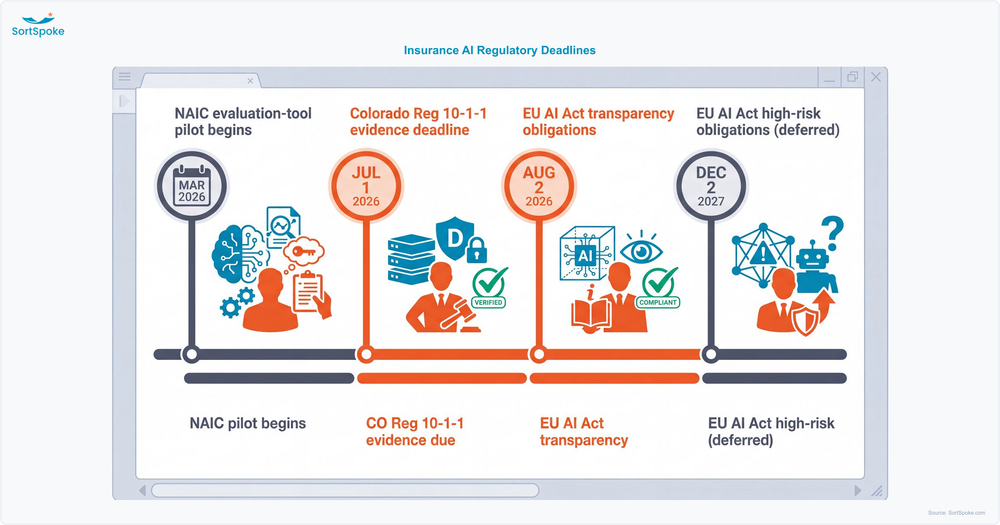
The NAIC AI Systems Evaluation Tool organizes an examiner's review into five focus areas. Walk through them with one question in mind — what would I have to produce, on demand, to satisfy each?
This is the place to be precise about the contrarian claim. Bias testing is on the examiner's list — so "regulators don't test your model" would be wrong. But notice what bias testing measures: the disparate impact of the output on protected classes, not the overall correctness of the model. A 99%-accurate model with a 6-point approval gap between demographic groups fails category three with flying colors. Accuracy and fairness are different axes, and only one of them is on the exam.
Here's the punchline that most governance checklists miss: four of the five categories collapse if you can't show humans were in the loop. Inventory needs an owner. Data governance needs an approver. Monitoring needs someone who acts on the alert. And the decision audit trail is, by definition, the record of who reviewed and authorized the outcome. Strip the human out of the workflow and you haven't just lost a control — you've lost the evidence the examiner came to see.
The closest analogue to what insurance carriers should expect didn't come from an insurance regulator at all. On July 10, 2025, the Massachusetts Attorney General announced a $2.5 million settlement with Earnest Operations, a student-loan lender, over allegations that its AI-driven underwriting produced a disparate impact on Black, Hispanic, and non-citizen applicants (Massachusetts AG).
The detail that matters for insurers: the AG didn't need a new AI statute to act. The case rested on existing consumer-protection and fair-lending law — the technology-agnostic body of law Asrow described. The findings read like the NAIC tool's failure modes: models untested for disparate impact, decisions applicants couldn't get explained, and no governance structure documenting who was accountable. The remedy required exactly what the frameworks ask for going forward — bias testing, written governance, and ongoing reporting.
If a state AG can reach a multimillion-dollar settlement over AI underwriting using laws that predate the technology, the absence of a finalized AI statute in your state is not protection. The exposure already exists. What's new is that examiners now have a structured tool to go looking for it.
This is the part most carriers haven't thought through. The hottest pitch in insurance AI right now is "agentic" — systems that don't just extract or score, but take autonomous action: routing, deciding, finalizing, with no human in the loop. The efficiency story is genuinely compelling. The compliance story is the opposite.
Every framework we've discussed presumes a human is accountable at the decision point. The EU AI Act is explicit that natural persons must be able to effectively oversee high-risk AI. An agentic system that takes action by design is, structurally, the thing that breaks that link. There is no reviewer whose action becomes the audit trail, because the design goal was to remove the reviewer.
And the market isn't ready for the burden. Deloitte's State of AI in the Enterprise 2026 found that only one in five companies has a mature governance model for autonomous AI agents (Deloitte, 2026), even as adoption climbs sharply. Carriers signing for agentic AI in 2026 are accepting a compliance liability that isn't written into the contract — and won't surface until the first exam or the first complaint.
This is not an argument against automation. It's an argument for being deliberate about where the human sits. The teams getting this right are the ones thinking carefully about how to staff a human-in-the-loop operation rather than designing the human out of it. BCG's framing on human oversight reaches the same conclusion from the strategy side: even an AI-first insurer needs the human firmly in the loop.
Here is the connection that nobody currently ranking for "AI governance insurance" makes explicitly. The three demands — inventory, audit trail, human accountability — aren't features you bolt onto a model. In a human-in-the-loop architecture, they are produced by construction.
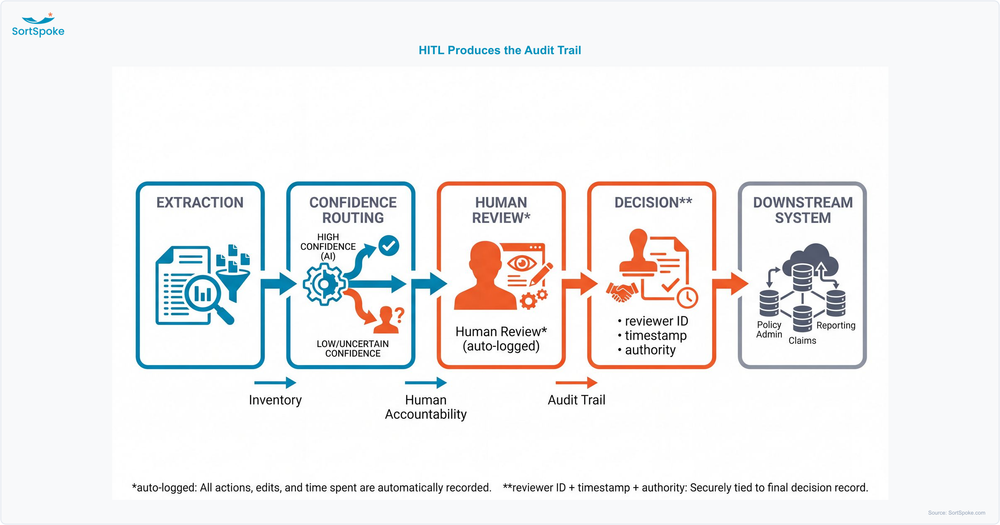
This is why human-in-the-loop is better understood as a compliance architecture than a product feature. It's also the throughline behind why so many AI initiatives stall: in 78% of insurance AI pilots never scale, the blocker is rarely accuracy — it's that nobody trusts an output they can't see, explain, or stand behind. The same visibility that builds internal trust is what produces the regulatory record. SortSpoke keeps humans in the driver's seat for exactly this reason — extraction is automated; the decision and the accountability stay with your team.
It's the same logic behind a defensible security posture. A SOC 2 Type 2 compliance posture matters for the same reason an audit trail matters to an examiner: it's continuous evidence that the controls actually operate — not a claim that they exist.
The uncomfortable data point: most carriers know there's a problem and still aren't positioned to pass. Grant Thornton's 2026 AI Impact Survey found that 44% of insurance executives say governance or compliance challenges have contributed to an AI project failing or underperforming — and only 24% are very confident they could pass an independent AI governance review within 90 days (Grant Thornton, April 2026).
The gap is usually not policy — most boards have adopted AI governance policies. The gap is evidence. The controls exist on paper, but the proof is fragmented across teams and tools, which is exactly what an examiner's structured questionnaire is built to expose. Closing that gap is a 12-month problem, not a 12-week one — it involves architecture decisions, data lineage, and workflow design you cannot sprint through the week before an exam. This is why it pays to pressure-test vendors early; our list of 9 questions before buying underwriting AI is built around the evidence a system can produce, not the demo it can perform. The same discipline applies upstream, where underwriting submission triage increasingly runs on AI and needs the same audit trail as everything downstream.
If you want a fast read on where you stand, work through these five questions. Each maps directly to something an examiner can ask for.
If any of those answers is "not quickly" or "not for every decision," that's the work — and it's worth starting before the deadline picks the timeline for you.
Regulators aren't asking whether your AI is accurate. They're asking whether you can explain how it reached a decision — and prove a human had authority over it. That's an architecture problem, not a compliance-team problem. Book a 15-minute demo → to see how SortSpoke's human-in-the-loop architecture produces the audit trail and human-accountability record by default — not as a bolt-on.
Commercial P&C Insurers Guide to Solving the Underwriting Bottleneck

Related articles



